
我们在开发过程中,有可能会遇到double类型中小数的精度控制的问题,比如数值的计算,小数位的控制等等,但是经常会遇到精度控制不当,导致计算结果出错的问题,以下为你介绍double的底层实现以及为什么会出现精度问题。
问题示例
看以下的代码
@Test
public void test(){
System.out.println(1.54-1.55);
}
输出结果,并不是我们预期的结果

进制转换
不过在此之前,可能还需要了解以下进制转换的知识,可以看看这篇文章Java中的double类型是怎么存储的
问题探讨
由这篇文章Java中的double类型是怎么存储的可知,1.54的二进制计算方式如下:
整数部分:
| 计算 | 商 | 余数 | 顺序 |
|---|---|---|---|
| 1÷2 | 0 此时商为0,不再计算 | 1 | 1 |
小数部分:
| 计算 | 结果a | a>=1?1:0 | 顺序 |
|---|---|---|---|
| 0.54×2 | 1.08 | 1 | 1 |
| 0.08×2 | 0.16 | 0 | 2 |
| 0.16×2 | 0.32 | 0 | 3 |
| 0.32×2 | 0.64 | 0 | 4 |
| 0.64×2 | 1.28 | 1 | 5 |
| 0.28×2 | 0.56 | 0 | 6 |
| 0.56×2 | 1.12 | 1 | 7 |
| 0.12×2 | 0.24 | 0 | 8 |
| 0.24×2 | 0.48 | 0 | 9 |
| 0.48×2 | 0.96 | 0 | 10 |
| 0.96×2 | 1.92 | 1 | 11 |
| 0.92×2 | 1.84 | 1 | 12 |
| 0.84×2 | 1.68 | 1 | 13 |
| 0.68×2 | 1.36 | 1 | 14 |
| 0.36×2 | 0.72 | 0 | 15 |
| 0.72×2 | 1.44 | 1 | 16 |
| 0.44×2 | 0.88 | 0 | 17 |
| 0.88×2 | 1.76 | 1 | 18 |
| 0.76×2 | 1.52 | 1 | 19 |
| 0.52×2 | 1.04 | 1 | 20 |
| 0.04×2 | 0.08 | 0 | 21 |
| 0.08×2 | 0.16 | 0 | 22 |
| 0.16×2 | 0.32 | 0 | 3 |
| … | … | … | … |
此时,会发现,小数部分计算出的第2位和第22位,出现了相同的,意味着又要开始进行相同的计算,意味着这是一个无限循环的数字。
由此可见,1.54 的二进制为:
1.1000101000111101011100001010001111010111000010100011110101110············
计算机不可能为我们存下这种无止境的数字,这种不正常的数字,double底层会自动按照double的限制,截取有效数位即可,所以,才会出现有些数字精度不准确的情况
继续,这篇文章Java中的double类型是怎么存储的中将其按照科学计数法的方式来计算double存储的结构,同理,对于1.54这种不正常的数字,我们也可以来试着计算:
通过科学计数法可知:
十进制:1.54
二进制:1.1000101000111101011100001010001111010111000010100011
科学计数法:1.1000101000111101011100001010001111010111000010100011 *
小数点移动位数:0位
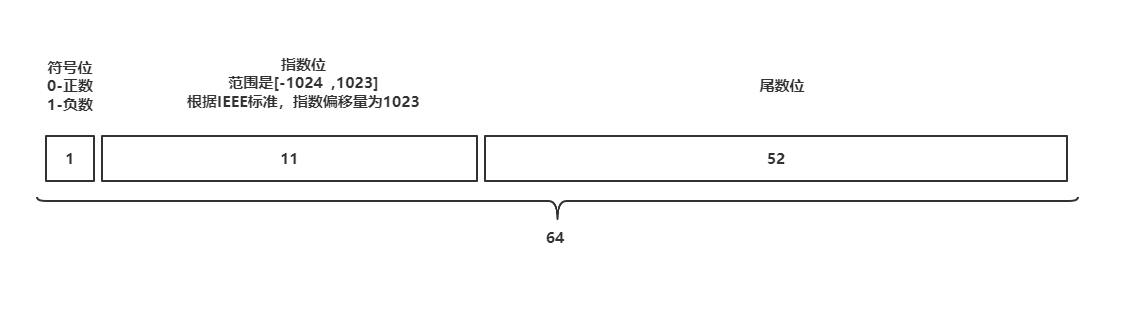
由上可知:double会自动将上面的无限循环的二进制截取为64位,所以,符号,指数,尾数,各保留对应的位数即可。
符号位:0 ----->因为是正数
指数位:
- 偏移量为:
- 指数位:
- 指数位二进制:1111111111
指数位的二进制为:1111111111 -----> 10个1
尾数位:1000101000111101011100001010001111010111000010100011
综上所述:1.54的double的在内存的存储方式为:
消除第一个0–符号位,因为是正数,消除第二个0–指数位前面的0可以直接不写
如果是负数,第一位必然是1,那么指数位就需要将前面的不管多少位0都要写出。
验证:
@Test
public void test() {
double test = 1.54d;
long testBits = Double.doubleToLongBits(test);
System.out.println(Long.toBinaryString(testBits));
}
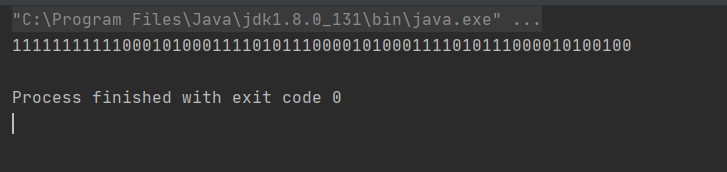
总结:最后的 00010100011 是不准确的,因为double只能取到这儿了,尾数只能存52位,所以说,有时候计算的时候,就会导致精度出错的问题,从而导致最上面的结果。